 Propuesta de valor
Propuesta de valor Propuesta de valor
Propuesta de valor.png "Cabecera Blog AWS (1)")
 ¿Fallo de Hardware? ¿Error interno? ¿Catástrofe meteorológica? ¿Ciberataque? ¿Caída de servidores?
¿Fallo de Hardware? ¿Error interno? ¿Catástrofe meteorológica? ¿Ciberataque? ¿Caída de servidores?
Si te suenan estas situaciones, seguramente te preguntes si tu estrategia de continuidad de negocio es capaz de sobrevivir ante ellas.
La ley de Murphy
Apuesto a que cualquier persona conoce o, por lo menos, ha escuchado hablar alguna vez de la Ley de Murphy. Si bien es cierto que, en realidad, Murphy no pronunció exactamente la conocida frase “si algo puede salir mal, saldrá mal” (aquí podríamos abrir un largo paréntesis y llegar al verdadero origen de la frase…). Lo que sí es cierto que ha quedado como un teorema que difícilmente escapa de nuestras vidas.
Y es que, a la hora de planificar, suele tenerse en cuenta el peor de los escenarios, aquel en el que algo no funciona como debería o no se comporta, de la manera que se supone que debería comportarse, o por restricciones de tiempo, algo sucede o no.

Traducido al mundo de IT en las empresas, podemos acordarnos del señor Murphy en varias situaciones:
- Internamente, cuando falla:
- Un servidor, discos, switches.
- Cualquier componente hardware de nuestro Centro de Datos.
- También veremos a nuestro amigo Murphy en las situaciones de fallos en la configuración.
- Provocando una pérdida de datos.
- O en situaciones en las que las aplicaciones de negocio pueden verse afectadas y no ofrecer el servicio deseado.
- Externamente, cuando agentes que están fuera de nuestro control provocan fallos por:
- Fenómenos meteorológicos extremos
- Secuestros por organizaciones cuyo único fin es obtener rédito económico tras acceder a nuestros sistemas y proceder a encriptar los datos de nuestra empresa,
- Fallos externos que impidan el correcto funcionamiento de nuestro negocio.
- O incluso, chantajes sobre información sensible de negocio, clientes, etc.
Para conocer las alternativas de cara a estar preparado con tu plan de continuidad de negocio, y que no se vea afectado por situaciones como las anteriores, te aconsejo “4 Claves para una Estrategia óptima de Disaster Recovery”
AWS Elastic Disaster Recovery Service (AWS EDR)
La nube juega un papel primordial en el planteamiento de una buena estrategia de CONTINUIDAD DE NEGOCIO (Disaster Recovery - DR). En este caso hablaremos de una solución de DR en modo servicio (DR as a Service – DRaaS).
En líneas generales, podemos decir que AWS EDR es la solución DRaaS de Amazon que nos permite automatizar el proceso de levantamiento de nuestro centro de datos en la nube ante el acontecimiento de un desastre. Gracias a ello, minimiza el tiempo de inactividad y la pérdida de datos con una recuperación rápida y fiable de nuestros entornos y aplicaciones, obteniéndose unos RTO y RPO mínimos.
Sus principales características son 3:
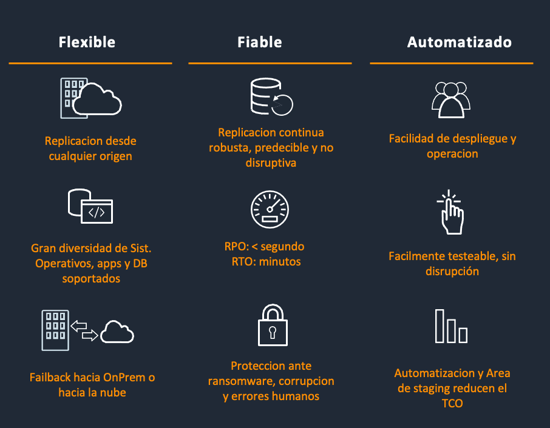
Por otro lado, de cara a tener un entorno de DR en la nube que cumpla con los 3 puntos anteriores, han de contemplarse las siguientes 4 fases:
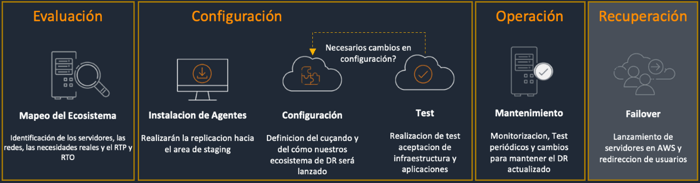
- Como puede verse en la imagen, necesitaremos Evaluar nuestro ecosistema de aplicativos de cara a configurar el servicio de acuerdo a las necesidades de RTO* y RPO** de cada uno de ellos, así como la foto que deseamos tener en la nube en caso de desastre (qué aplicativos, qué capacidad/dimensionamiento, entre otros).
- Una vez configurado, el servicio nos ofrece la posibilidad de monitorizar y testear que toda esa replicación se está realizando adecuadamente, permitiendo levantar entornos de manera rápida y ágil para demostrar que el sistema es capaz de levantarse de acuerdo con los parámetros establecidos.
- Lógicamente, dado que nuestros entornos van evolucionando, el servicio realiza un mantenimiento, ayudándonos a que tengamos los datos y operativa actualizada, de manera que levantemos los entornos desde el estado más actualizado posible.
- En caso de desastre, este servicio lleva a cabo la recuperación, es decir, automatiza el levantamiento de los entornos en función de la parametrización que hayamos hecho anteriormente, contribuyendo a que tengamos un RTO y RPO mínimos.
Hasta aquí, podríamos decir que no aporta nada nuevo comparándolo con las metodologías de Disaster Recovery tradicionales (On premise), pero es porque no hemos hablado de las implicaciones en coste, como veremos en el último punto.
AWS EDR: Funcionamiento
Para entender el funcionamiento de AWS EDR (o Disaster Recovery Service – DRS), nos basaremos en el siguiente diagrama de arquitectura:
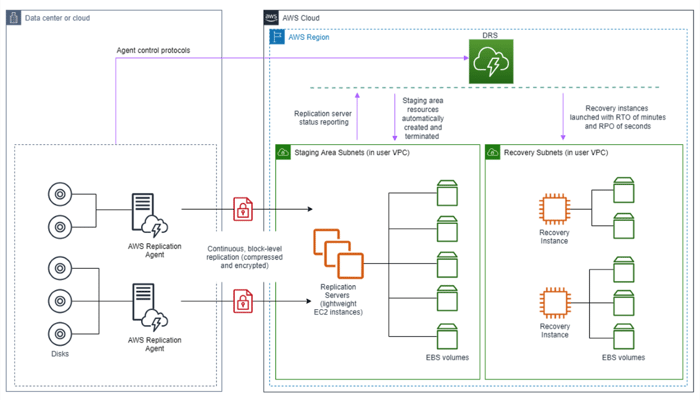
Básicamente, tenemos lo siguiente:
- Agentes instalados en las máquinas origen (AWS Replication Agent) cuya función será la de sincronizar a nivel de bloque y de manera continua los volúmenes de cada uno de los servidores on premise con volúmenes en la nube (EBS Volumes).
- Instancias de replicación (Replication Servers), que serán las encargadas de recibir las actualizaciones (cambios a nivel de bloque) y aplicar los cambios en los volúmenes del área de staging.
- Instancias de Recuperación (Recovery Instance), que serán aquellas instancias lanzadas a causa del acontecimiento de un desastre en nuestro centro de datos.
El servicio AWS EDR será el encargado de, a partir de las copias de los volúmenes on premise, levantar instancias “gemelas” a las máquinas (físicas o virtuales) que tengamos en on premise, de manera que tengamos un gemelo de nuestro centro de datos en la nube.
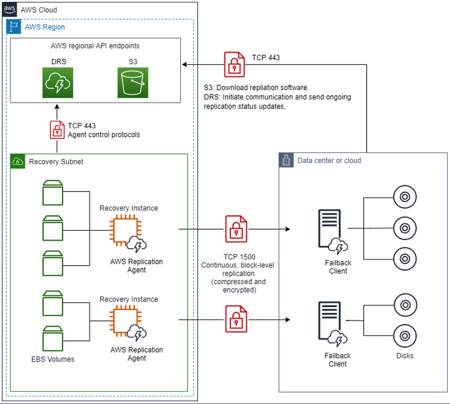
En este caso, el proceso será el inverso:
- Agentes instalados en las instancias AWS (AWS Replication Agent) enviarán la información de forma continua y a nivel de bloque hacia nuestro Datacenter.
- Agentes instalados en las máquinas de nuestro datacenter (FailBack Client) procederán a la sincronización de los datos para que los cambios que se hayan producido mientras la nube ha estado ejerciendo de centro de datos principal se vean reflejados cuando restauremos nuestro datacenter on premise.
AWS EDR: Coste
Sencillo y directo
El coste del servicio es mínimo, infinitamente inferior al coste de administrar un centro de datos de contingencia, y en modalidad pago por uso.
Veamos los elementos a tener en cuenta:
-
Almacenamiento:
-
- Tamaño de almacenamiento de los volúmenes en origen.
- Granularidad necesitada para la recuperación Point-in-Time, es decir, cada cuanto tiempo necesitamos almacenar un Snapshot y, lógicamente, la cantidad de información que ha sido modificada desde el momento en que se almacenó el anterior Snapshot, que determinará el tamaño de los mismos.
- Tamaño de almacenamiento de los volúmenes en origen.
-
Instancias de Replicación:
-
Número de servidores replicados:
El servicio tiene un coste fijo por hora para cada uno de los servidores origen replicados. El coste actual (septiembre 2022) es de unos 20 €/mes por servidor.
Mejora tu Plan de Contingencia con AWS Disaster Recovery
Puesto que en una buena estrategia es primordial:
-
El análisis de la situación.
-
La determinación de la criticidad de los entornos.
-
Y el diseño del protocolo de actuación.
RTO* y RPO**: Conceptos fundamentales y fáciles de entender en lo relativo a Disaster Recovery. En base a ellos se puede planificar y decidir qué tipo de soluciones son necesarias para cada negocio.
- RPO (Recovery Point Objective). Volumen de datos en riesgo de pérdida que la organización considera asumible.
- RTO (Recovery Time Objective). Tiempo durante el cual una organización pueda asumir una falta de funcionamiento sin afectar a la continuidad del negocio.

Blogs relacionados:
> 4 Claves para una estrategia óptima de Disaster Recovery
> Ciberseguridad y Cloud ¿Amigos o Enemigos?
