 Propuesta de valor
Propuesta de valor Propuesta de valor
Propuesta de valor
¿Dónde están mis bloques?
Siguiendo en la línea del tema sobre vectores de datos que vimos en ¿Cómo se ordenan los datos en un cubo OLAP de EPM?, una casuística particular que se da en el motor de cálculo EPM Essbase (que, recordemos, trabaja con bases de datos multidimensionales) es la "dispersión" de datos.
Comenzando por el principio, en una base de datos multidimensional vamos a tener varias dimensiones que cruzan entre sí. Algunos cruces pueden ser altamente representativos o esenciales para el negocio en cuestión, y, por lo tanto, tendrán una alta probabilidad de contener datos.
Por ejemplo: en un cruce entre cuentas contables (o analíticas) y periodos, prácticamente todos los cruces van a tener datos; todos los meses se pagan salarios, o suministros, o hay ingresos (¡al menos, así esperamos que sea!). Sin embargo, puede haber dimensiones que, por su naturaleza, tienden a la dispersión.
Dimensiones que tienden a la dispersión
Este puede ser el caso de: un cruce entre clientes y productos. No todos los clientes compran todos los productos, y extendiéndonos un poco más, probablemente tampoco los compran todos los meses. El fenómeno de la dispersión se produce de manera natural en casi cualquier aplicación de EPM, y tanto más es así cuando introducimos dimensiones del tipo producto, cliente, proveedor, acreedores, etc.
Ante este fenómeno, diferentes herramientas tienen distintas formas de gestionar la dispersión. En el caso de herramientas más antiguas, la dispersión podía llegar a ser un problema que hacía impracticable ciertos objetivos que debía cumplir la aplicación (te estoy mirando a ti, OFA). En cambio, en herramientas más actuales y de nueva generación, la dispersión se gestiona de manera automática para que ni desarrolladores ni usuarios tengan que preocuparse por este fenómeno (como podría ser el caso de OneStream).
Ejemplo de dispersión
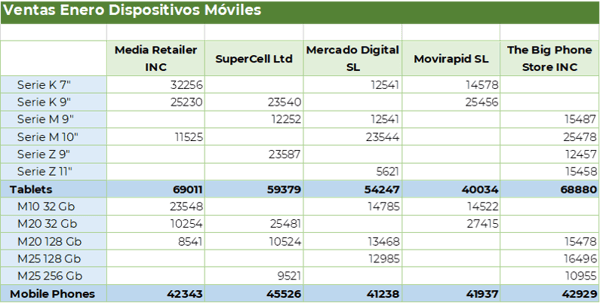
Centrándonos en la familia Hyperion Planning y sus análogos en Cloud (PBCS, EPBCS, etc), estaríamos en una situación intermedia. EPM Essbase, el motor de cálculo de Hyperion Planning, es capaz de gestionar la dispersión hasta cierto punto, pero requiere de anticipación a la hora de diseñar el modelo y de programar los cálculos. Así, del total de dimensiones del modelo (hasta 14), antes de construir debemos analizar cuáles van a ser dimensiones densas y cuáles van a ser dispersas. Por defecto, Account y Period van a definirse como "dimensiones densas", mientras que el resto serán "dimensiones dispersas". Esto sigue los ejemplos que hemos visto más arriba.
Esta definición de "densas" y "dispersas" tiene impacto directo en cómo Essbase va a almacenar los datos. El concepto de "vector de datos". es perfectamente válido para Essbase, pero lo cierto es que Essbase almacena la información en "bloques", donde cada bloque está formado por todos los cruces posibles de dimensiones densas. Dentro de un bloque van a existir todas las celdas correspondientes a dichos cruces, tanto si contienen dato como si no. En cambio, un bloque solo existirá si hay una combinación de dimensiones densas que haga referencia a ese bloque.
Ejemplo de densidad
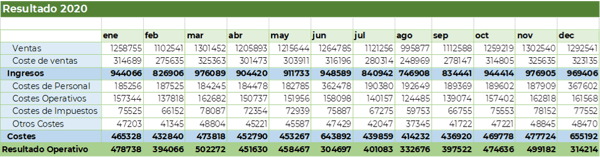
Un ejemplo: supongamos un modelo hipotético con 100 cuentas y 12 periodos, donde la cuenta y el periodo son dimensiones densas. Esto significa que cada bloque de este modelo contendrá siempre 1200 celdas. Supongamos, también, una tercera dimensión de producto, donde tenemos "Producto 1", "Producto 2", … "Producto N". Si cargamos datos para "Producto 1", dejando el resto vacío, el único bloque que existirá almacenado en Essbase será el correspondiente al "Producto 1". 1200 celdas dedicadas sólo al "Producto 1". Essbase solo creará aquellos bloques que contengan datos. De ese modo, a la hora de calcular, Essbase puede optimizar las operaciones y centrarse en los bloques qué sí existen.
Y aquí llega uno de los principales dolores de cabeza para los desarrolladores: la creación de bloques
¿Qué ocurre si necesitamos hacer una operación dentro de una dimensión dispersa? Supongamos por un momento que el Producto 2 es complementario del 1. Por ejemplo, el pan y la mantequilla. Podemos estimar que por cada 10 barras de pan venderemos 1 envase de mantequilla, de modo que podríamos calcular en nuestro modelo que "Producto 2" = 0.1*"Producto 1". Lo que va a ocurrir en la mayoría de ocasiones es que Essbase no va a ser capaz de generar los valores en "Producto 2", porque el bloque correspondiente al "Producto 2" aún no existe. En estas circunstancias, no siempre fáciles de anticipar ni de detectar, el desarrollador ha de recurrir a ciertas funciones o activar determinadas opciones del sistema para que el cálculo cree el bloque correspondiente al "Producto 2", posibilitando así que se generen los datos correspondientes.
Aquí va un símil que suelo utilizar: en un archivo Excel, cada hoja sería un bloque con dos dimensiones densas (las filas y las columnas), y las hojas constituirían una dimensión dispersa. Suponed que tenéis una tabla en la hoja 1 con datos de 2020, y queréis crear una tabla igual en la hoja 2 para calcular los datos de 2021 en función de los de 2020 que hay en la hoja 1. Pues bien, para poder crear esa tabla y obtener datos en la hoja 2, primero será necesario que exista esa hoja 2. Del mismo modo que si la hoja 2 no existe no podemos calcular datos sobre ella, Essbase no puede calcular datos sobre un bloque que aún no existe.
Si alguna vez os encontráis colaborando en un proyecto con un equipo de EPM y empiezan a hablaros de problemas de dispersión y de creación de bloques, ¡podéis estar seguros de que no es ninguna milonga!
¿Te gustaría leer algún tema en concreto sobre EPM?
¡Cuéntanoslo!
O pincha aquí para encontrar más artículos sobre EPM

Blogs Relacionados:
> Analytics: implementación EPM e integración del BI en tu empresa
> Enterprise Performance Mangement para eliminar a tu competencia
> One View Financial Statement. Optimiza tus informes financieros
> 5 Razones para Implementar una Solución de Gestión de Tesorería
> Caso de éxito | Automatización presupuesto en Gran Consumo
> Oracle BI y Hyperion Essbase: simulación de procesos de producción